

Real Time Segmentation - BiSeNet Network | Paper Insights
Paper: https://arxiv.org/pdf/1808.00897.pdf
Implementation: https://github.com/CoinCheung/BiSeNet
Dataset example: https://www.cityscapes-dataset.com/examples/
The other day I came across the code of this paper, I tried it out and I saw that the performance was quite good and the results were great with a well trained network, so now I'm doing a app based with this model so there is not better paper to start the Paper Insights Series.
This method achieves really good segmentation performance in the order of hundreds of FPS in a top GPU, without compromising in the resolution of the image, that's awesome if you want to use the model in real time, but it's also great to use "offline" due to the high speed of the model, you can serve a lot of people at a time.
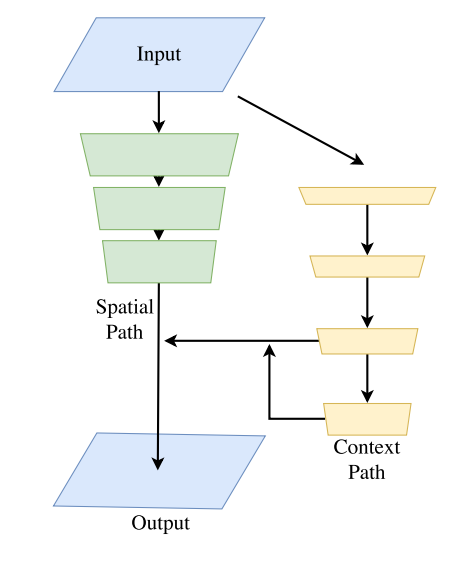
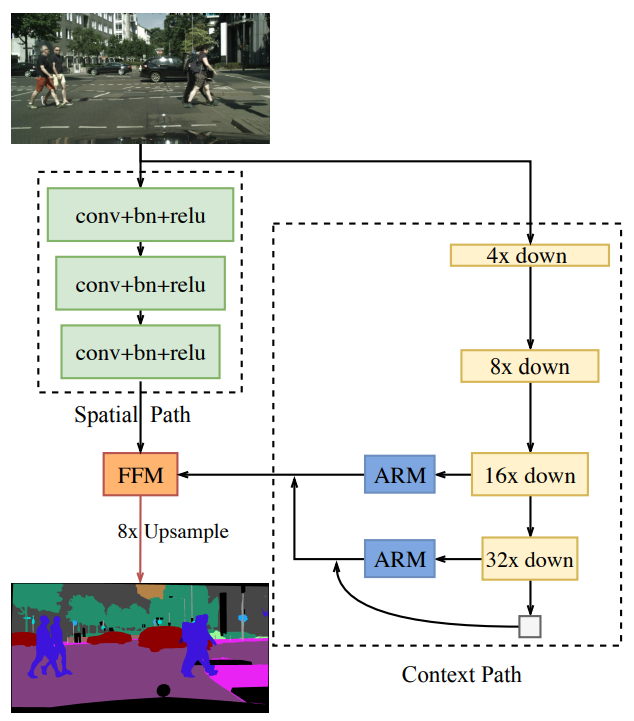
This is done using the BiSeNet: Bilateral Segmentation Network, which constitutes of a Spatial Path, a Context Path and in addition of Feature Fusion Module and Attention Refinement to improve accuracy, let's see what all of this is about.
Recent methods to accelerate models, accordingly the research in this area are:
- Reduce input size, this leads to poor quality inference and decreased accuracy.
- Prune the channels, it weakens the spatial capacity.
- ENet drops the entire last stage of the model, This leads to poor discriminative ability since the model can't accomodate for larger objects.
One approach to solve loss of spatial details is to use an U-Shape Structure, this technique has 2 drawbacks,
- It reduces speed, due to extra computation on high-resolution feature maps.
- It doesn't recover enough spatial resolution in shallow layer, which is lost in the pruning/cropping
The authors propose the BiSeNet with the Spatial Path and the Context Path, the first takes care of the spatial information, the second one takes care of the shrinkage of receptive fields, later we see what this concepts are if you are not familiar with them.
To improve Accuracy the Feature Fusion Module (FFM) and Attention Refinement Module (ARM) are proposed without a huge cost in speed.
Related concepts:
Receptive fields: Receptive fields are defined portion of space or spatial construct containing units that provide input to a set of units within a corresponding layer. The receptive field is defined by the filter size of a layer within a CNN.
Spatial information: CNN encodes high-level semantic information with consecutive down-sampling operations, in the semantic segmentation the spatial information is very important so modern approaches try to encode as much spatial information as possible, using things like dilated convolutions (preserves size of spatial size of the feature map) or "larga kernels" (enlarge receptive field)
Context information: Common methods to get more context information are enlarge receptive field or fuse different context information.
Other methods are using different dilation rates in convolution layers to capture diverse contet information.
ASPP is used to capture context information of different receptive field.
Spatial Path
Due to the use of dilated convolution to preserve the resolution of the input image and capturing sufficient receptive fields with pyramid Pooling module and "large Kernel", This indicates that spatial information and the receptive field are crucial to achieve high accuracy.
In terms of Real Time Segmentation, modern approaches use small size input images or lightweight base model to speed up, this leads to loss of spatial information due to the image resolution, and poor spatial information because of the channel pruning.
With this the Spatial path use to preserve spatial size of the input image and encode plentiful spatial information.
The spatial path contain three layers, each compose of:
- Conv: stride = 2
- Batch Normalization
- ReLu
In the end we left of with a feature map with 1/8 of the original image size.
Accordingly to the paper this econdes rich spatial information due to the large spatial size of feature maps.
Context Path
The context path is designed to provide sufficient receptive field, the receptive field is really important for performance in the semantic segmentation task.
The context path utilizes a lightweight (Xception) model and Global Average Pooling to provide large receptive field.
The pretrained Xception model is use to downsample the feature maps, obtaining large receptive field, which encodes high level semantic context information.
After the lightweight model there is a global average pooling, Finally the up-sampled output feature of global pooling and the features of the lightweight model are combined.
To fuse the features of the last two stages of the lightweight model a U-shape structure is used, alongside the ARM:
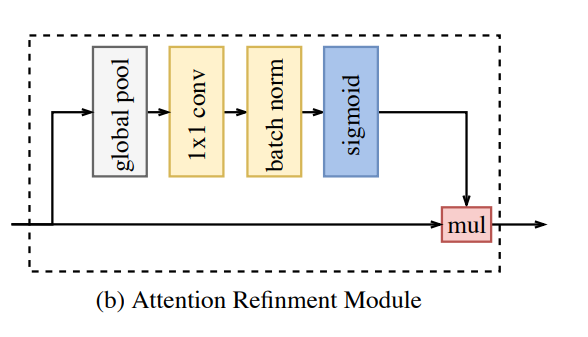
This module refines the output feature of the last two stages, integrating the global context information without up-sampling operation, it doesn't require that much computation.
Putting it all together
Feature Fusion Module
The two path encodes in different levels of abstraction, the Spatial Path encodes rich detail information (low level information), the Context Path well context information (high level information) so the Feature Fusion Module is use to fuse these features.
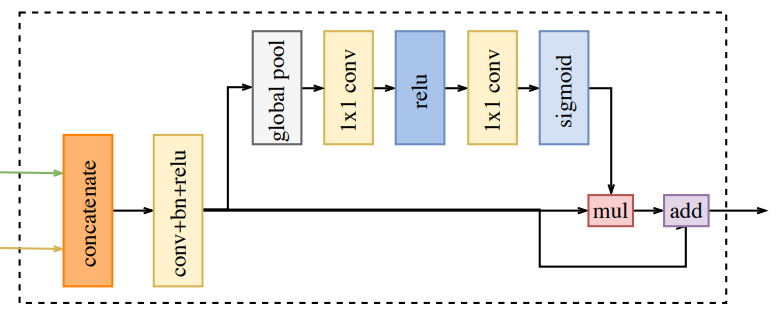
First the two path are join together (concatenation)
Batch normalization is used to balance the scale of the features
Global pool of the concatenated features to a feature vector and compute a weight vector.
This weight vector can re-weight the features, which amounts to feature selection and combination.
Loss Function
Well now let's take a peek at the loss function utilized in the model.
All the loss functions are Softmax loss, a principal loss is used for the output of the whole BiSeNet and also 2 auxiliary for output of the Context Path
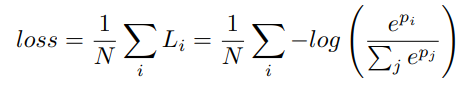
p is the output prediction of the network.
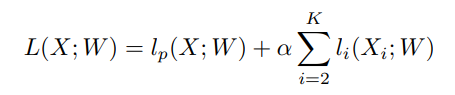
α is used to balance the weight of the principal loss and auxiliary loss, is set to 1 in the paper.
Where lp is the principal loss of the concatenated output.
Xi is the output feature from stage i of Xception model.
li is the auxiliary loss for stage i.
The K is equal to 3 in our paper. <- Couldn't find this in the paper
The L is the joint loss function.
Only the auxiliary loss is used in the training phase.
Implementation Protocol
Network: We apply three convolutions as Spatial Path and Xception39 model for Context Path. And then we use Feature Fusion Module to combine the features of these two paths to predict the final results. The output resolution of Spatial Path and the final prediction are 1/8 of the original image.
Hyperparameters:
Batch size = 16,
momentum = 0.9
Weight decay = 1e-4
lr = 2.5e-2 initial, "poly" learning rate strategy is used.
Data Augmentation:
Mean subtraction
random horizontal flip
random scale = {0.75, 1.0, 1.5, 1.75, 2.0}
random crop to fix size.
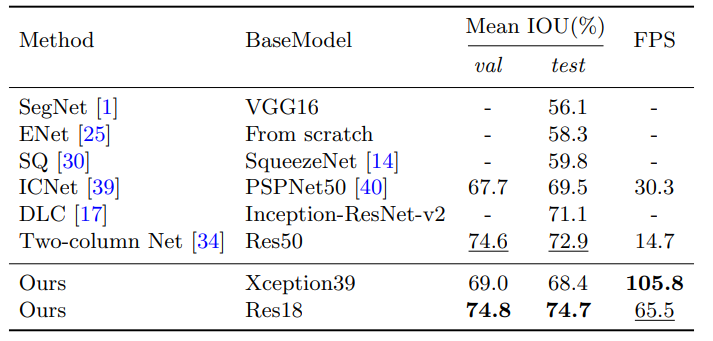
Some Results:
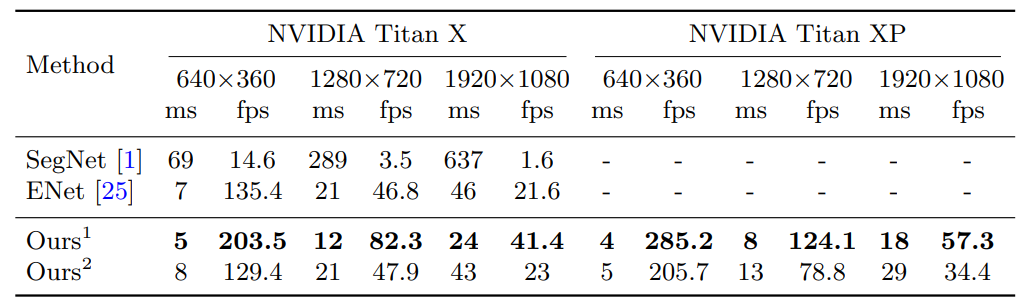
They are achieving incredible results 80fps at 720p or 41fps at 1080p, this can process a 720p video of 10min at 30fps in 3:45 minutes.
This model has incredible results and with an incredible speed, it's really suitable for real time, or high speed offline segmentation. The first model is using Xception39 and the second one is using Resnet18 it has worse fps performance but better accuracy.
Well this was my first Paper Insights, thanks to the authors of the paper for the amazing work, had a lot of fun reading it really interesting stuff, I'm going to do a video about this in the future. Thanks for reading 😄


